


Freight Pricing across US mainland
Issues & Objectives
- The trucking company was facing challenges in agreeing on right freight price with truck operators.
- Only a few skilled agents with knowledge of certain lanes could negotiate successfully
- Suggest appropriate fare to be offered on load-boards for full truck loads (FTL) freight on a specific lane (Origin-Destination) for a particular date, equipment & load features, in the continental US market
Results
- A combination of very accurate localized models and broader hub-based models gave ~95% accuracy
Project information
Techniques
Forecasting
Client
Large Trucking Company
Industries
Supply Chain & Retail
Location
US
Challenges
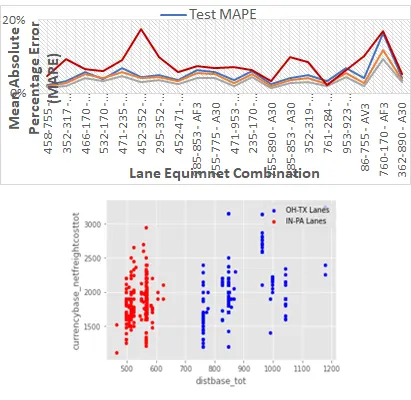
- Very sparse data: 70,000 loads (over 3 years), spread over 70 lanes and 42 equipment to answer a problem for any lane across the continent
- Apparently erratic prices: e.g. OH-TX lanes (750-1200 mi) are priced same as IN-PA (500-600 mi), for same equipment!
- Prohibitive price of historic data from Truckstop or DAT meant only generic third-party data like Fuel prices & CASS index
Solution
- PDFs need to be OCR’d to load texts in it
- Ensemble modelling – A very large number of models were developed
- Solution deployed using MLFlow, integrated with DataLake and transaction system
What we build, how it performs – Explore our work!
Would love to hear your thoughts!


Telecom Scorecard
Issues & Objectives
- Scorecard for telecom customers for a Malaysian Bureau
- Bureau variables as well as information from litigation/legal suit and electronic transfer data used in the model
- Logistic Regression and a machine learning model to replace generic bureau score for these customers
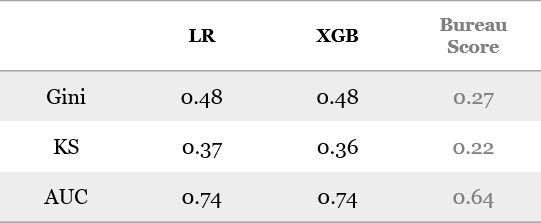
Benefits
- Performance of both LR and XGBoost scores better than generic bureau scorecard
- Implementation code in python facilitated easy integration
Project information
Techniques
Risk Analytics
Client
Telecom Customers for a Malaysian Bureau
Industries
Financial Services
Location
Malaysia
Challenges
- Data in batches
- Data change during analysis resulting in frequent rework
- Variable recoding towards the end of modeling work
Solution
- Data processing and analysis carried out in python
- Scorecard with reason code for LR model
- For machine learning method, XGBoost model showed better performance than Random Forest model
- Score for ML model was generated
- Score interpretation using LIME (Local Interpretable Model Agnostic Explanation)
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Searchable Contracts for Public Works Authority
Issues & Objectives
To develop ML based system for searching contents in contracts:
- Contacts are present with the client in pdf format with scanned images
- We have to convert it into readable formats and then index them in database
- Our aim is to build a ML based system that can accurately find the search term in headings of the contracts
Results
- API which takes contact number and search term as an input was built
- It outputs the potential pages where the term could be found
- The client’s team then integrates them in their PDF reader to enable direct search and read operations
Project information
Techniques
Text Analytics
Client
Regulatory Authority in Qatar
Industries
Public Sector & Education
Location
Qatar

Challenges
- The Contacts PDFs needs to be run through an Optical Character Recognition system
- We are only searching for topics/headings, therefore we only need to extract the headings from the text
- Handling and Searching in a large amount of data
Solution
- PDFs need to be OCR’d to load texts in it
- Headings were extracted from the texts with a high recall using Tika
- Headings were indexed in solr to determine top results
- The top results are then passed to ML to determine the best match among them
- MariaDB (SQL) database is used
- The deployment framework is Flask API + Gunicorn
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Address/Entity Matching
Issues & Objectives
To develop ML based system for matching addresses and entity names:
- Same address or entity names can be written in few different ways
- It may have spelling issues, order might be different, abbreviations may exist
- Our aim is to build a ML based system that can accurately match the addresses and entity with the ones already in our database
Results
Test recall (KPI) for different models are given as below:
- Address Matching: 87.47 %
- Entity Matching: 88.62 %
Project information
Techniques
Text Analytics
Client
Corporate Data Aggregator
Industries
Public Sector & Education
Location
India
Challenges
- The database is mostly on addresses and entities (company names & person names)
- Different models are being built for address and entity separately
- Entity matching can be tricky as it contains both person name and company name which ideally should require different set of features
- Handling and Searching in a large amount of data
- Annotation of data consistently by multiple SMEs was a challenge
Solution
- Solr is used to search an address/entity from the database and to determine top 10,20 or 30 results
- The top results are then passed to ML to determine the best match among them
- MariaDB (SQL) database is used
- The deployment framework is Flask API + Gunicorn
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Topic Prediction for EdTech
Issues & Objectives
To develop ML based system for predictions for Online Test Preparation Systems:
- Students are asked questions for there exam preparations
- They may face issue with solving questions
- Our aim is to build a ML and NLP based system that can accurately predict the topic/chapter of that question
- Detecting appropriate topics removes the need for manual tagging and enables faster and frequent uploads of new questions/tests
Challenges
- The questions are primarily on 4 subjects: Physics, Biology, Mathematics and Chemistry
- Questions are available as text, but many of them contains images of text, figures, equations and chemical diagrams
- Converting equations and chemical diagrams to appropriate formats for ML processing
Project information
Techniques
Text Analytics
Client
EdTech
Industries
Public Sector & Education
Location
India

Solution
- Natural Language Processing (NLP):
- Images: Converted to text using appropriate Optical Character Recognition for different subjects
- Text: Converted to vectors using Word2Vec
- Algorithm(s): Deep Neural Network + Random Forest
- Storage: AWS Cloud
- Database: MariaDB (SQL)
- Deployment Framework: Flask API + Gunicorn
Results
Test recall (KPI) for different Subjects are given as below
- Physics: 92%
- Biology: 88%
- Chemistry: 89%
- Mathematics: 89%
What we build, how it performs – Explore our work!
Would love to hear your thoughts!
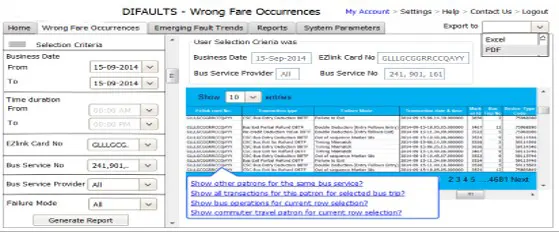
Smart Analysis on Bus Transportation System
Issues & Objectives
Transport regulatory authority in Singapore commissioned a system to
- Automatically discover wrong fare incidents and flag commuter’s cards affected by wrong fare charging; and
- Detect emerging fault trends in fare collection equipment so that corrective action could be taken in a timely manner
Challenges
- Large data 15 million transactions per day, which translates to more than 5 billion historical transactions in a year needs to be processed to identify fault patterns and trends
- The data consisted of financial, operations, transit and events data of buses
Project information
Techniques
Forecasting
Client
Transportation Authority
Industries
Public Sector & Education
Location
Singapore

Solution
- Data Storage: Hadoop and MySQL
- Query Tools: Hive and SQL
- Algorithms: rmr (Parallel versions of R) and Java
- Reporting and Dashboards: Pentaho
Results
Robust solution in use for over 2 years allows pro-active rather than reactive maintenance
![]()
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Child Support Case Management Predictive Analytics
Issues & Objectives
- There are two parents in every child support case. One is the Custodial Parent (CP) – the parent who lives with the child the majority of the time and has the primary day-to-day responsibility; the other is the Non-Custodial Parent (NCP) who also has important responsibilities. An aggrieved CP may appeal to the state to enforce child support by the NCP
- The project objective is to predict the collection category of cases based on its past payment pattern and various attributes
Challenges
- Extremely large data – Approx. 300,000 cases per month
- Available data and relevant variables differ from state to state. Predictive models built for four states so far
- Collection categories definition
Project information
Techniques
Risk Analytics
Client
Child Support Service
Industries
Public Sector & Education
Location
USA

Solution
- Multinomial Logistics Regression technique was used to build the predictive models
- Models were developed for 4 major states in the United States
Results
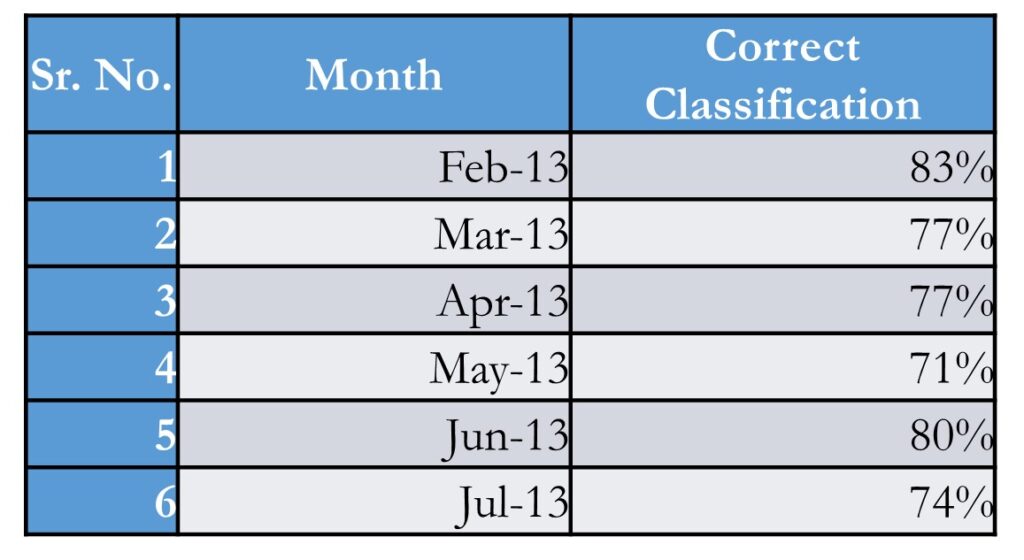
- The accuracy of prediction for a dataset of 12 months was 71–83%

What we build, how it performs – Explore our work!
Would love to hear your thoughts!
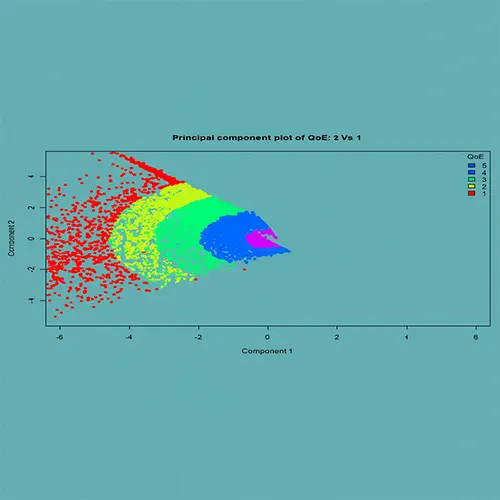
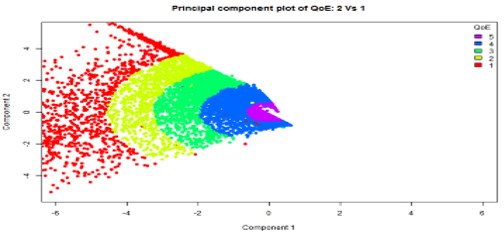
Scoring Customer Quality Experience (QoE)
Issues & Objectives
- To develop a score of the customer quality of experience (QoE) based on objective factors such as such as number of stalls, frame drops, ghost sessions, and play delay for an internet video service provider
Challenges
- Extremely large data – Over 2.5 million records
- Data inconsistencies
- Traffic variation at different time of the day
Project information
Techniques
Risk Analytics
Client
Telecom
Industries
Public Sector & Education
Location
India

Solution
- Applied Principal Component Analysis (PCA) technique to build models for scoring
- Developed 4 different models using different variable transformation techniques
- Scored 8,800 records/sec
Results
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Distribution Analytics – Demand Forecast
Issues & Objectives
- A Singapore based company provide multi country mobile platform for distributed sales representatives who gets updated information on demand forecast, recommendation and target sale
- They wanted to build appropriate models for forecast
- All output were to be pre processed in nightly batch run and saved in a centralized database
- A customized software for managerial decision making was also needed
Benefits
- Batch run for a dataset of 60K transaction take less than 10 minutes producing multiple output tables
- Experiment with customer segments and view a particular subset for any discount/promotion
- View the position of customers and the recommendation to be made
- Review the profile of DSR and extent of target achievement
- Employ Various methods and visualize actual vs forecast
Project information
Techniques
Forecasting
Client
SaaS Provider
Industries
Supply Chain & Retail
Location
Singapore
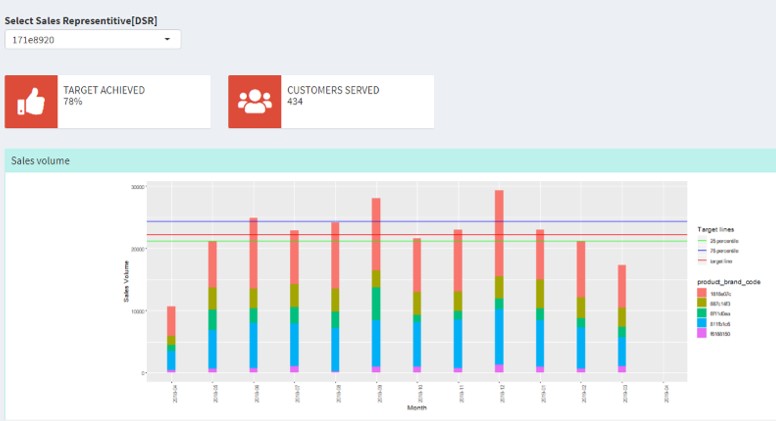
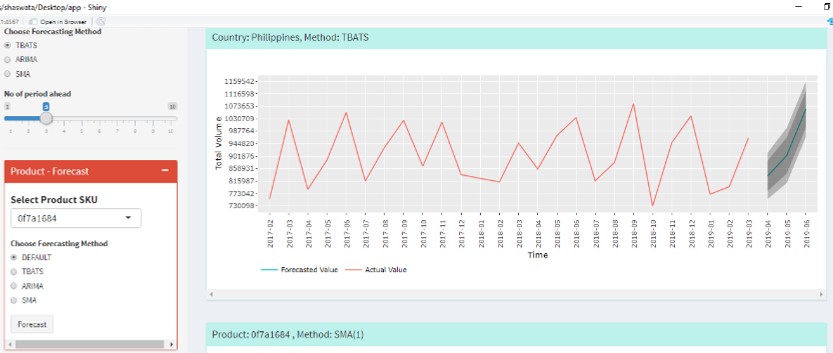
Challenges
- High attrition of DSRs made it hard to collate a time series sales data
- Customer base changes between transition from one DSR to another
- Intermittent sales data for about 30% of customers
- Discontinued or new product SKUs with short history of sales data
Solution
- Software developed in R Shiny
- K-means and hierarchical clustering and time series forecasting methods were used
- Batch code is developed in R with input and output link to client database
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Real Estate Valuation Analytics
Issues & Objectives
- Loans by a large financial company in India to real estate developers are repaid in a mix of cash and inventory
- The projects under development will only be ready for launch (sale to buyers) a number of years after the loan is taken
- The financial company therefore requires prediction of property prices at time of launch and a number of years post launch
- They commissioned Smart to build customized software for such price analytics
Benefits
- Property valuation at launch as well as comparison with competition in few clicks
- View relative position of the project in the same locality
- Valuation in next 5 years post launch is instantaneous
Project information
Techniques
Forecasting
Client
Large financial company in India
Industries
Supply Chain & Retail
Location
India
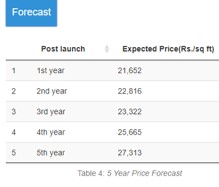

Challenges
- Data missing for 50% projects
- Data mismatches
- One-third of the real estate project records could not be used for modeling due to missing price or inventory data
- Project amenities specified using free text; same amenity could have multiple descriptions
Solution
- Software developed on R Shiny platform
- An NLP technique, Word2Vec was used for specification and amenity data
- Clusters of micro markets were formed by hierarchical clustering method
- Algorithm for forecasting velocity of sale was developed
- Link with the database for comparison of any new project
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Application Scorecard
Issues & Objectives
- SMEs play a crucial role in the Indonesian economy, contributing significantly to employment and economic growth. Our client, a non-bank financial institution based in Indonesia, offers a range of financing services to individuals and businesses
- The objective of this project was to develop application scoring model for SME. The SME portfolio was new to the client which had been recently acquired by a multinational bank headquartered in Australia. The scoring model was used for SME loan origination decisions
Benefits
- Process Automation
- Ensures Consistency in decision making
- Predictive modelling replaces gut feel
- Scores recalibrated with default data after sometime
Project information
Techniques
Risk Analytics
Client
Bank Lending to SMEs
Industries
Financial Services
Location
Indonesia

Challenges
- Scaling up operations in accordance with Indonesian government directive
- Very small number of data points ≈ 400 making it difficult to obtain reliable results through predictive modelling
- The SME portfolio was new so the history of defaults had not been well established
Solution
- Bootstrapping was used to overcome the limitation of a small sample
- Reject rates were taken as a surrogate for default rate
- High quality scorecard was developed
- Model Gini = 66.74 (Gini > 55 indicates a high quality scorecard)
- Model KS = 53.85 (KS > 45 indicates a high quality scorecard)
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Calibration of Expert Scorecard by ML Methods
Issues & Objectives
- For the first time in India, a scorecard was developed for the client to keep vigil on the listed companies to avoid potential financial disaster
- Scorecard was based on financial as well nonfinancial events such as auditors, board of directors, litigation, news etc
- The task was to refine expert scorecard with ML methods
Benefits
- Discriminatory power of the calibrate scorecard was found to be higher than the expert scorecard
- Apply a decision overlay which enhanced the predictive power of the scorecard
- Better separation between GOOD and BAD companies in modelled score
Project information
Techniques
Risk Analytics
Client
Corporate Data Aggregator
Industries
Financial Services
Location
India

GBM Score
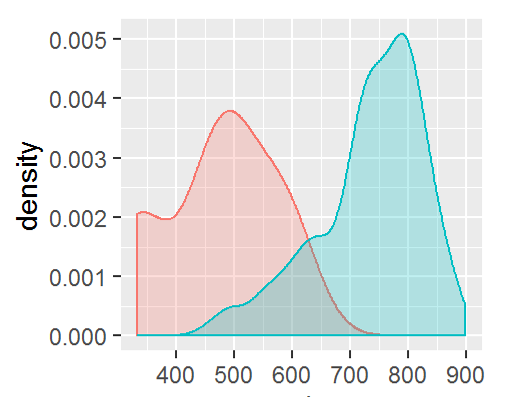
Expert Score
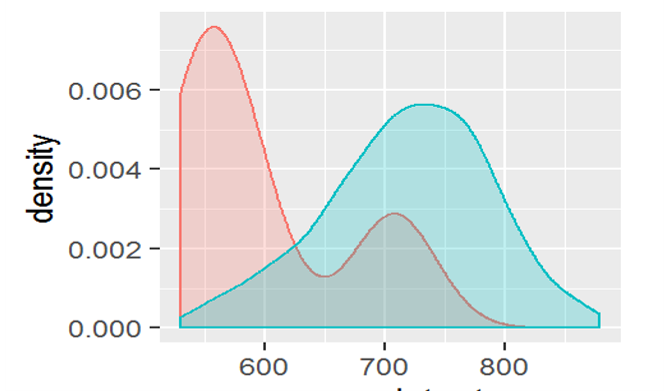
Solution
- Decision tree, Random forest and Gradient boosting were used to obtain weights of the events
- ML methods were run in h2o
- Models for listed and unlisted companies were built
- Separate weights for listed and unlisted companies were used to arrive at the consolidated score of parent companies
Challenges
- Listed and unlisted flag was incomplete in the database
- Many companies had large number of missing data
- Frequent modification of event logic
- Running ML models and processing score with new weights took several hours posing a challenge to multiple iteration
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Application Scorecard For Auto Loan
Issues & Objectives
- Application scorecard for sub-prime customers
- Review and recalibrate scorecard
- Use insight data to improve alignment between underwriting rules and scores
Challenges
- Methodology for current scorecard not well documented
- Scores not aligned with underwriting rules
- Data in batches – Credit history, product information, loan terms in different files from different time periods
- Performance available only for 8% TTD population who take up loan from 55% approval
Project information
Techniques
Risk Analytics
Client
Auto Loan Provider
Industries
Financial Services
Location
UK

Solution
- Data collation to align all variables from same time-period was carried out using R for analysis
- Customers classification using domain knowledge and statistical methods – Decision tree and cluster analysis
- Multiple scorecards each with superior performance than existing scorecard
- All scorecards rescaled to have similar odds
- Scorecard as a linear function for easy integration with loan origination system
- Reviewed underwriting rule and corporate reporting system and recommended changes


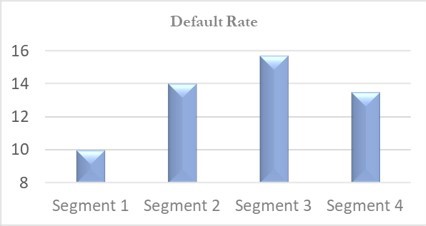
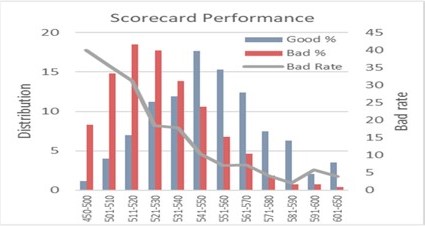
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Credit Scoring for Leasing Company
Issues & Objectives
- A large company in UK finances lease of office equipment, primarily to small and medium companies with ticket size less than £10K
- Leased items depreciates rapidly and seizure of collateral does not recover the debt
- The company currently cherry picks customers who seldom go bad
- They want to expand customer base while controlling risk
- For this they want a scorecard to replace rule driven underwriting for better screening
Benefits
- Scorecard developed by Statistical method
- Scrutiny restricted to high scorers reducing manual work by a factor of 5 -10
Project information
Techniques
Risk Analytics
Client
Equipment Leasing Company
Industries
Financial Services
Location
UK
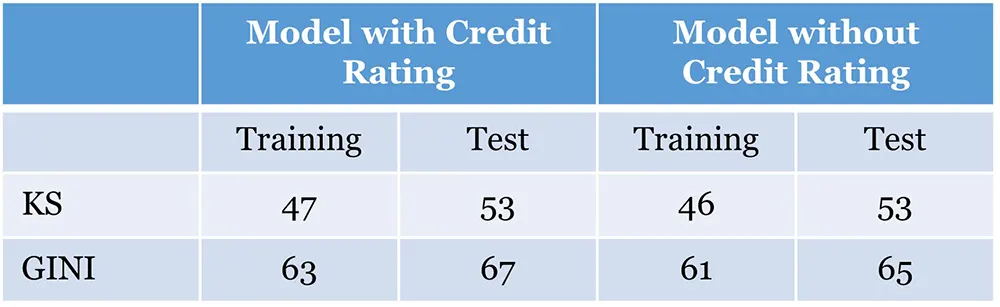
Challenges
- Company book identified only 2.5% bad lease – payment history data was fraught with inconsistent figures
- After incorporating liquidation/insolvency/dissolution status and rating from credit bureau record, the incidence was boosted to 12%. The process classified non takers of loan to Good and Bad by a logical method and not by reject inference
Solution
- Model developed by R program
- 2 scorecards with and without credit bureau ratings were delivered
- Discriminatory power of the scorecards were high as seen from high KS and GINI
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Fraud Scoring for Insurance Claims
Issues & Objectives
- A major insurance company in Singapore used to manually examine each travel insurance claim to identify potentially fraudulent one
- Suspicious claims were subject to a more detailed investigation
- This involved considerable manual effort & inconsistent processes
- The project objective was to develop a score to identify potentially fraudulent claims which would be subject to greater scrutiny
Benefits
- Process automation, ensuring consistency, cost saving and increased accuracy
- Scrutiny restricted to high scorers reducing manual work by a factor of 5 -10
Project information
Techniques
Risk Analytics
Client
Travel Insurance Provider
Industries
Financial Services
Location
Singapore
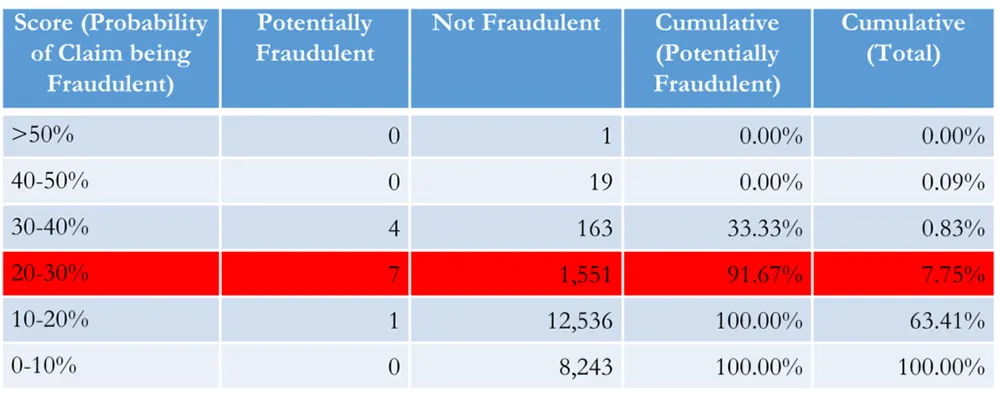
Challenges
- Data included 77,445 claim records of which only 120 had been determined to be potentially fraudulent
- So identified potentially fraudulent claims are rare events (0.15%) and therefore hard to detect
- It was however expected that there could be a large number of undetected fraudulent claims
Solution
- Gradient Boosting – a powerful machine learning algorithm was used for detecting potentially fraudulent cases
- Substantial lift demonstrated. – on the client test data set it sufficed to examine 7.75% of all claims to identify 91.67% of all fraudulent claims
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Credit Scoring for Micro Finance Provider
Issues & Objectives
- A Multi-finance company providing financing facilities for small and medium enterprises in Indonesia
- The objective was to develop multiple portfolios for different loan types
- Link the scorecard to core banking system to produce instant score at the time of application
Benefits
- Process automation, ensured consistency, decreased manual work and increased accuracy
- Generation of scorecards in real time with performance measures
- Variable transformations are automatically accounted in scoring population
- Deployment of the model and scorecard for scoring new applicants
- Easy monitoring of score with the help of interactive reports
Project information
Techniques
Risk Analytics
Client
NBFC
Industries
Financial Services
Location
Indonesia
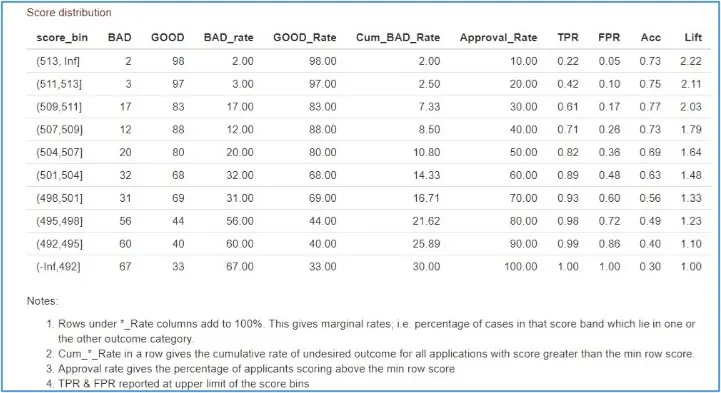
Challenges
- On account of data security, the company developed the model in-house. No data was shared with Smart
- Most of the data fields are in local language
- Smart guided the whole process remotely with only one on-site visit and many hours of online consulting. This involved detailed analysis of numerous variables for each scorecard
Solution
- The whole process is automated with Smart proprietary software, ACreS
- 4 portfolios were built one each for Retail SME, Corporate SME, Retail Vehicle Loan and Corporate Vehicle Loan
- In absence of core banking system, webservice is created to input data and receive instant score
- Newly entered data is stored in a database
What we build, how it performs – Explore our work!
Would love to hear your thoughts!

Scoring Return of COD Consignments
Issues & Objectives
- To develop a scoring model to identify consignments likely to be returned, in case of Cash on Delivery (CoD) payments for one of the largest e-tailer distributors.
Benefits
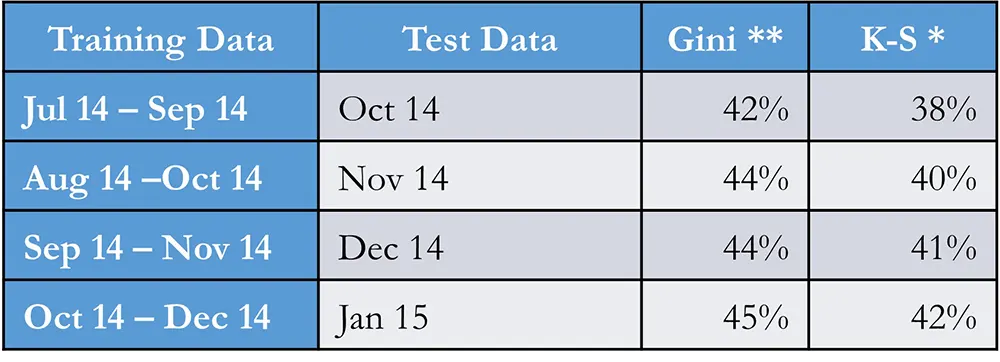
| *K-S 36 – 45 | High separation for application scorecard |
| **Gini36 – 45 | Average separation, definitely useful |
Project information
Techniques
Risk Analytics
Client
E-COM Courier Company
Industries
Financial Services
Location
India
Challenges
- Extremely large data – Over 2.5 million records
- Data inconsistencies
- Traffic variation at different time of the day
Solution
- Univariate analysis to identify significant variables
- Clustered clients based on number of orders from a specific vendor
- Developed various models and recommended the most suitable one
What we build, how it performs – Explore our work!
Would love to hear your thoughts!