


Connect apps, files, APIs, and databases; standardize schemas; de-duplicate and reconcile reference/master data so analytics and ML are trustworthy.
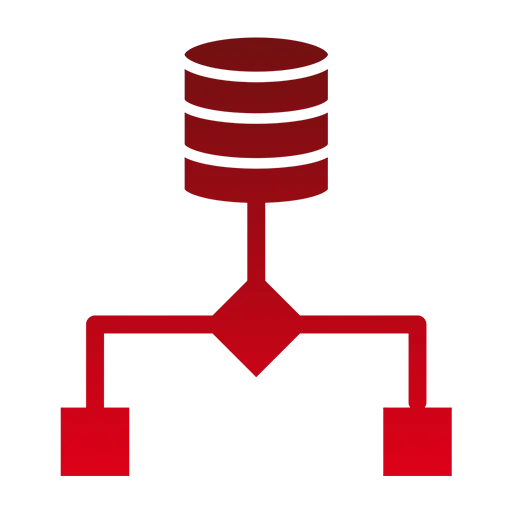
Monitored, retry-safe pipelines with SLAs; feature pipelines ensure consistent inputs for analytics and ML.
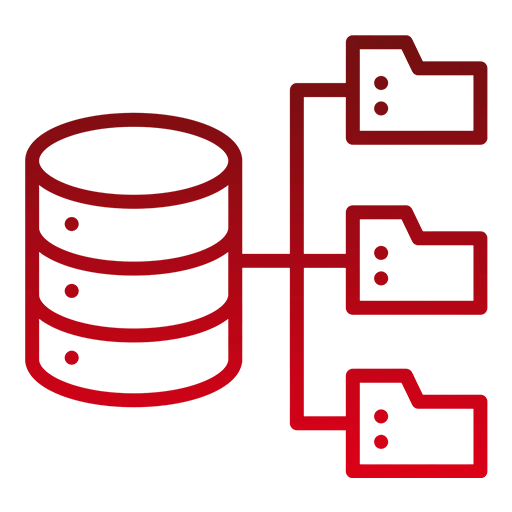
Layered (raw → cleaned → curated) storage on cloud or on-prem; a simple semantic layer so business terms mean the same thing everywhere.

Freshness, lineage, drift, and spend dashboards; CI/CD for data changes with quick rollback.
Versioned data/metric services for BI tools, apps, and model serving; role-based access controls and audit trails.

High-volume fare/ops event processing (15M/day) on Hadoop/MySQL with Hive/SQL and parallel R/Java; powered proactive maintenance insights.

OCR + heading extraction + Solr indexing with an API that returns likely pages for terms—integrated into a PDF reader.
Two-stage Solr + ML architecture with ~87–89% recall on addresses/entities at scale; API deployment for production use.
